
16. 神经网络,概念实体,以及精神交流
4月6日更新:
- L2 regularization
相当于做陶艺,用柔和的手,在陶瓷(weights,即概念)上制造曲面
- L1 regularization
相当于用锋利的刀,削木头,制造工艺品(weights,即概念),有棱有角
- Elastic net regularization
是L2和L1的结合,是细腻的工匠,削一下材料,再用磨砂打磨
- Max Norm constraints
限制w最大值,相当于有一个模子,挤压一下,超出的部分会被挤回去
- Dropout
随机使某些weight一定几率不改变,而改变另外的weights
相当于理发师使用带有锯齿的剪刀修剪头发,一缕头发有长有短,清新自然。
关键词: 观察者效应;神经网络;概念实体;精神交流;量子纠缠
俗话说,日有所思,夜有所想。广涵同学晚上思考了以下三个问题:
- 【Digital Image Processing】: Hough Transform,如何在N个点中用O(n)的复杂度找到所有的经过M个点的共线?
- 【Computational Intelligence】: Fuzzy Logic,如何使用Modus Ponens和Compositional Rule of Inference,以及如何来做defuzzification?
- 【Machine Learning】: MultiLayer Perceptron(MLP)的backpropagation,到底是如何做的,背后的原理和机制是什么?
前两个问题(不是本文重点)很快想明白了,而第三个问题(是本文重点的前言)我思考的时候产生了许多奇思怪想,越想越活跃,以至于“长夜漫漫,无心睡眠”——
backpropagation,从根本上说,是一个优化(optimization)问题的解法。目标函数(Taget Function)是一个高维度函数,或者形象点说是一个高维度曲面。函数的变量是神经网络的权重(weights),有多少个变量,就有多少个维度。输入(input),是已知的常数(independent variables, 对于一个固定的input example来说它们是常数);核函数(Kernel)的参数,也是已知常数;神经网络的结构本身,也是已知的。(读到这里,如果已经开始对本文丧失兴趣的话,请跳到后半部分,直接脑洞大开——)
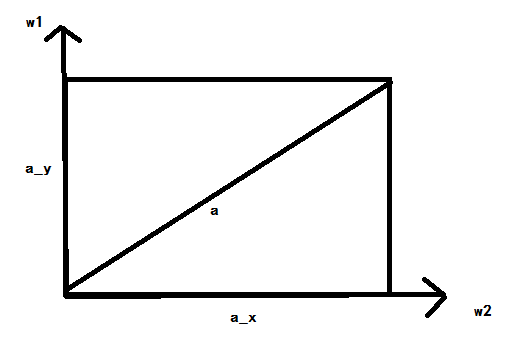
举个例子,如下函数是一个可轻松想象的曲面。
z = x^2 + y^2 (公式1)
这里x,y是变量,对应着神经网络里面的weights,用w表示的话应该是:
target= w1^2 + w2^2(公式2)
用梯度下降(Gradient descent)的方法来做optimization找最小值,就是顺着曲面找gradient最大的方向。通俗点说,就是顺着坡度最陡的方向下山,能最快地下到山底。当我们固定了learning rate(方向向量的具体长度)和momentum(梯度下降的动量和势头)的时候,实际上找坡度方向等价于找一个长度固定的方向向量,或者说是找到对应各个维度(例子中是,w1, w2两个维度)的方向的向量分量。找到在各个维度的长度分配权重,就是找gradient的根本。
广涵认为(blog.guanghan.info),我们可以把计算输入常量经过神经元得到输出的过程用矩阵表示,但我们知道(如果不知道请见最下方Appendix),矩阵的含义是把元矩阵经过线性变换得到的空间形状,其行列式是这个变换导致的体积变化。比如说一个N*M的矩阵,把一个N维度空间里由M个顶点组成的元矩阵,变换为对应此矩阵的高维物体形状。MLP甚至是deep learning的CNN等网络中,各层神经元由元矩阵经过不同的形状变换得来,是同源同宗。 问题在于,矩阵的变换都是线性的,只是在各个方向上进行比例拉伸和平移——这导致得到的高维形状是一个个平面组成的,就如三维空间中六面体一样,每个面是平滑的没有弧度。
为了使得神经元的weights可以对应一个任意形状的物体,我们需要一个核函数。核函数引入了非线性,把每个面加上了褶皱效应。同样的一个核函数,可以使得曲面千变万化。
有人可能会问,深度学习里面,输入的参数才是变量吧?实际上,这里我们需要转换一下思维。深度学习里面有batch learning和online learning两种方式,拿online learning举例——对于每一个需要被学习的observation来讲,我们知道一个输入向量,比如说是28*28= 784维的vector,经过若干层网络,输出是1024维。因为在training过程中,对于一个observation,我们也是知道它应当的输出的label的(因此MLP实际上也是supervised learning的过程),所以target function应该是:
z= f(x0, w) – y0 (公式3),
其中x0和y0分别是输入和输出,是已知的。可以看出来,optmization是求z的最小值,变量是w。backpropagation的过程实际上是从输出开始求每一个神经元的最优化的weights,然后逐级前溯,得到所有神经元的最优化weights。对于每一个神经元来讲(非输入),它都是由前一层中连接到它的神经元构成的一个高纬度曲面,因此有许多个高维曲面。
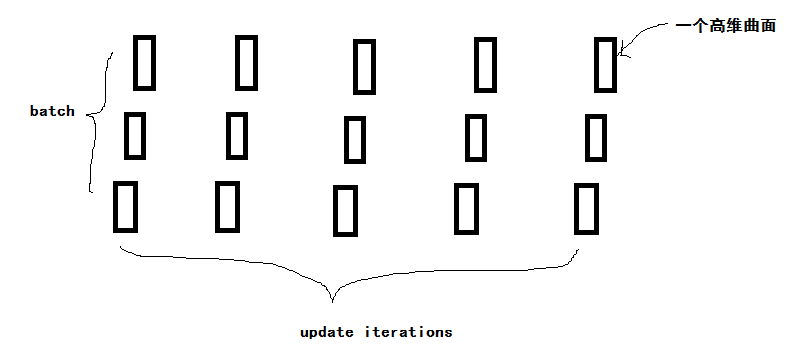
对高维曲面,我们用gradient descent的方式,找到各个维度的向量分量长度,知道如何对各个weights进行update。在online learning中,对第一个高维曲面进行初次的weights update之后,再根据第二个高维曲面的函数,进行第二次的weights update,如此循环往复。每一次update的时候我们更换了observation example,曲面改变了,而每个曲面的形状不同,导致各个曲面上的同一高维点的gradient方向可能是矛盾和相左的,因此很可能我们经过很多次back and forth的挣扎,才逐步走到了谷底,得到最优值。而在batch learning中,我们用一个batch(多个observation example)作为一个单元,每次批处理了整个batch之后才update weights,才按照某个方向在各个曲面上往下滑。最终是求整体意义上的最优,即让w满足,平均意义上它对应的所有曲面的点都是很低的。因此,综合了多个observation example的曲面后,找一个整体意义上的下降方向,确实能够更快地达到谷底。
 (图2)
(图2)
如图2,每一个iteration要对多个高维曲面进行计算,找到平均意义上的最优方向(对不同的高维曲面的下降向量进行加权)。进行多次这样的iteration之后,我们达到所有曲面平均意义上的最低点。
最后得到的weights,就是我们training得到的结果,它是 y= f(x, w0) ,对应另外一个高维曲面。它对于M维的输入变量x,都有一个N维的输出y作为响应。它是一个映射,也是一个概念。x是对于一件事物的描述,y就是对于这个描述的判断结果,w0就是这一事物的概念。
(学术严肃时间结束,下面开始正经儿的胡思乱想了!作为一个神棍的脑洞大开,千万不可尽信。世界奇妙有趣,是我们期望的,如此便好。)
所以,综上所述,概念也是一种存在——概念其实就是一个高维度的实体。我们知道(反正电影里都是这么演的),高度发达的文明之间语言虽然不通,但可以用共通的办法来表达含义——用形状表达意思,表达概念,表达真理。
比方说,用正态曲线表达不均匀性,表达宇宙的真理——熵增的最大化方式。
比如,圆,x^2+ y^2= 1。代表此消彼长,代表阴阳。正弦和余弦分别是阴阳的动力,x、y分别是阴和阳。太极就是圆和正余弦,是中原人朴素的智慧。道生一,一生二,二生三,三生万物。
别小看朴素的智慧啊,稍微包装一下——信号由弦组成,万物由弦组成,弦的震动形式决定的微观粒子的质量和速度,种类及形态。 弦理论中的brane,把一个微观粒子看成任意维度:点是零维,弦是一维,还有更高维。 (弦理论,M理论,统一理论啥的,多么高大上,可是老祖宗早就朴素地表达相关哲学了啊喂)。
正如机器学习中神经网络试图模拟的一般,人的大脑神经元有激发和不激发之分;并且神经元之间的非线性神经递质释放机制,潜藏着高维度。就像微观粒子里面藏着高纬度一样,这也是精神的广阔和非物质的原因。非物质,指的是非宏观物质,它们具有量子性。
精神是高维度的存在。在我们的三维映射不存在了,在其他的某三维的映射仍有可能存在。
思想可以碰撞,精神可以交流,是因为大脑虽然没有物理接触,但高维度上的精神可能交融了。万物有灵,万物互联(听着好耳熟诶喂?),宇宙精神,观察者效应,皆与此有关。
对于观察者效应——观察本身作用在了量子上,是实实在在的作用。因为精神本身是高维度的,观察本身会在高维度上对微观粒子进行影响。
而量子纠缠,根本原因是三维空间里观察的量子之间看似没有关联,它们在高维度上却是紧密相联的。它们之间不需要所谓的“瞬间的信息传递”,因为它们本身就是一体的。
为什么宏观世界上我们不能靠主观思想改变一个结果呢?一方面,那是因为宏观世界是所有精神(不只是人)共享的,它是所有已知或未知的观察者共同作用的结果。所有精神实体与宏观世界的作用导致它不会产生任何偏执的结果。观察结果,是原本的实体和精神实体相互作用的结果。主观唯心主义的值得称道的地方在于,它意识到了世界不过是精神观念影响的世界,是主观影响并接收的世界,而非所谓的“本源的、客观的”世界;而它局限的地方在于,夸大了个人精神对世界的影响程度。唯物主义的局限在于完全忽略精神对物质世界的影响;但因为宏观物质世界里这种影响微乎其微,在大部分条件下是可以作为相对真理的,算是唯物主义的贡献吧。(Analogy:正如牛顿运动定律在宏观低速的条件下可以作为相对真理一样;而相对论描述的是更为普遍的一种状况,当物体的运动速度接近光速的时候,“时间、距离”和速度的关联就显示出来了。)
对于观察者效应,可能有唯物主义的同志反对说,这种不可观测性是逻辑的,而非主观的——比如双缝干涉实验,当存在任何可能测量到结果的实验条件产生的时候,干涉便会消失。其实这种观点忽略了一点——当人们改变实验条件,确信这种实验条件能够测量电子通过哪一个孔的时候,这种信念已经造成了影响。
所谓的“概率云”,是人类用以描述“量子态”的一种方式而已。所谓的“波函数”的“坍塌”,或者用我朴素的表达来讲,可能性的消失,正是宇宙本身对自己的一种开辟。正如一团泥土捏成小人,虽然泥土本身具备着可能性,然而消除其它的可能性才是创造。
咳咳,如果你还能忍受我的脑洞的话,我继续往悬了说吧——相同观念的人们在高维度上有相同或相似形状和位置的概念实体。如果一个种族集体在头脑中造神,那么就有了概念上的实体。利用集体观念的人可以操控他人。
高维度的东西不稳定,就像微观粒子不稳定一样。因此高维度的概念,会利用三维世界的实体的行为,稳定下来形成宏观实体。这就是为什么潜意识里的观念,会影响我们的行为,变成我们写的一堆代码,画的一篇涂鸦,或者堆的一个雪人儿。
生物的显性合作在宏观,比如码农通过Git来合作写代码;而隐形合作是高维度世界中的思想概念共享,和共同计算,姑且叫做“生物云计算”(怎么又听起来好熟?)——这通过所谓的“潜意识”完成。以前我只知道,显意识是进行逻辑判断的,运算很慢,而潜意识能够做大量的组合排列的试错计算,在清醒后通过显意识把运算结果进行逻辑判断,语义理解,和概念性的总结——这就是所谓的“灵感”。实际上潜意识不止是如此而已,它把我们的思想碎片与他人的思想实体进行联结,让我们的精神进行交融;不止是概念上的共享,甚至运算力也能分享,大数据和云计算什么的,跟脑电波比起来,都弱爆了好吧。(额,我承认……以上都是我一厢情愿的推测和愿望,你咬我吧!)
透露一个秘密——有人面壁十年,是在用精神接受来自高维度的信息,传输的内容很大所以需要不被阻断地长时间传输。一些信息甚至可以赋予他特异能力。
佛教许多思想大概、也许、差不多是这么被传递过来的,加上了悟道者本人的理解。他估计也分不清哪些是传递来的,哪些是自己的理解。——就如我现在一般。凌晨一点四十五了,我得睡了。下次咱们继续扯~
宁广涵 10/31/2015
Appendix:
【矩阵的本质】是运动的描述
(如果有乘法,左边的矩阵描述的是右边的矩阵的运动方式。如果没有矩阵乘法,只有一个矩阵,那么这个矩阵的含义是元矩阵变换过来的运动方式)
x1 x2 x3
y1 y2 y3 每一row是一个维度的量,通过把2维空间坐标点的每一个维度都进行3种线性变换的叠加,获得新的空间位置
1 1 1
*
[m1, m2, m3]’ 这是一个需要被变换的一个2维空间坐标点
=
[x, y, 1]’
假设被变换的矩阵不是一列,而是好几列(比如N列),那么实际上是对一个N个顶点的object进行空间变换。
【行列式的本质】是描述矩阵对应的线性变换对空间的拉伸程度的度量,或者说物体经过变换前后的体积比。
那么如何求行列式呢?
如何求逆矩阵呢?
怎样才是可逆的呢?
如果矩阵进行变换的时候,有一个维度变为了0,那么相当于失去了变换前的信息,无论如何也不能恢复这部分信息了,即不可逆。
这种情况下,矩阵的秩是小于N的。行列式等于0。