
导语
人体姿态识别,又称为人体关键点识别,在2016年底至今,发展迅速。单人的人体姿态识别已经在著名公开数据集MPII和LSP上取得了90%以上的准确率。多人关键点识别,是指在自然场景下识别多人的姿态;与单人姿态识别相比,人物并没有预先定位,也没有生成人物在中心的图像ROI区块。2016年开始,COCO数据集开始增加人体关键点识别的任务,实际上指的就是多人的人体姿态识别。
在人体关键点领域,与COCO齐名的数据集有MPII Multi-person Dataset,是MPII单人姿态数据集的一个补充。该实验室Max Planck Institute for Informatics(MPII)在2017年推出了一个更大的数据集:PoseTrack,并相应推出了第一届的PoseTrack Challenge。该挑战赛对应三个任务:单帧多人姿态识别,多帧多人姿态识别,多帧多人姿态跟踪。该数据集的训练集包括300个视频,验证集包括50个视频,测试集有208个视频。数据集公开后成为人体关键点跟踪领域最大最权威的数据集。
第一届PoseTrack挑战赛是ICCV 2017的一个workshop。在挑战赛结束之后,PoseTrack对所有注册用户公开,并推出Leaderboard来实时更新在该数据集上最新的结果。每个注册的方法最多可以提交四次结果,每次结果提交的间隔不得短于72小时。京东大数据与智能供应链组宁广涵主导的开源项目openSVAI在该leaderboard的多人人体关键点识别任务上排名第二,超过第七名Facebook团队的Mask R-CNN方法9个百分点。
今年,作为ECCV 2018的一个workshop,MPII实验室联合Google、Amazon等业界知名公司推出了第二届的PoseTrack挑战赛。在第二届挑战赛中,PoseTrack的数据集得到了扩充,训练集被扩充到593个视频,验证集拥有74个视频,测试集有375个视频,总体扩充了将近一倍。并且,为了吸引更多高校和业界公司的参与,数据集服务器的官方上传格式改变成了与COCO兼容的形式,可以让参加COCO人体关键点检测比赛的团队可以更容易地参与PoseTrack的挑战赛。
京东大数据与智能供应链组参与了这次挑战赛的两个项目:多人的人体关键点识别和关键点跟踪,均取得了第六名的成绩。在没有使用外部数据集的方法中,openSVAI在PoseTrack挑战赛两项任务中的排名分别是第一和第三。
以下是对参赛方法 [1]的干货分享——
方法介绍
人体关键点跟踪是一个新兴的任务,目前有自顶向下和自底向上两种主流的方法。自顶向下的方法是先进行人物的检测,再对检测到的人物对应的ROI进行单人关键点识别,最后将视频中不同人物的关键点通过数据关联的方法赋予一致的ID。
人体关键点跟踪的评估标准和多物体检测(Multi-object tracking)是相似的,用MOTA指标来评估。这种评估准绳会惩罚丢失(missing)、错误(false positive)和不一致(mis-match)三种情况,比人体姿态识别的PCK/OKS评估准则更加严格。
我们遵循自顶向下的方法,顺序地进行人物检测,单人人体姿态识别,多人姿态追踪。这三个模块相互独立,但通过openSVAI进行标准化的结构数据传递。

Pose Tracking有很多应用。openSVAI在人体姿态跟踪的基础上增加分割模块,可以实现更多功能,比如对自动驾驶视频的分析。
(1)物体检测模块
人物检测模块我们使用了标准物体检测的方法:deformable FPN网络 [2]。使用的是在COCO上预训练的80类的物体检测模型。当然,如果使用专门针对人体检测的数据集(比如CrowdHuman)进行增广,并且单独训练人物这个类别,检测模块的准确率仍然可以获得提升。
我们测试了deformable R-FCN和deformable FPN两个网络结构,并且分别测试了ResNet101和ResNet50两个backbone。经过对比,选择了deformable FPN作为物体检测网络。我们根据验证集给出的关键点位置确定bbox的大致位置并将其扩大20%,以此作为人物检测的真值。以此作为真值,我们测试并评估了两个网络的物体检测的准确率。下面图表显示,在不同的IoU阈值下,两种方法的precision和recall。显然,deformable FPN的表现更好。
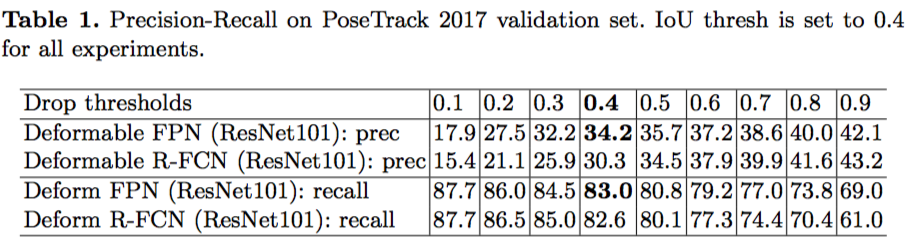
那么,是不是检测的结果好,人体姿态识别和跟踪的准确率就一定更好呢?的确是的。下面图表中显示,在固定后续两个模块的情况下,使用不同检测方法时,人体关键点识别和跟踪两项任务在验证集上准确率的对比。
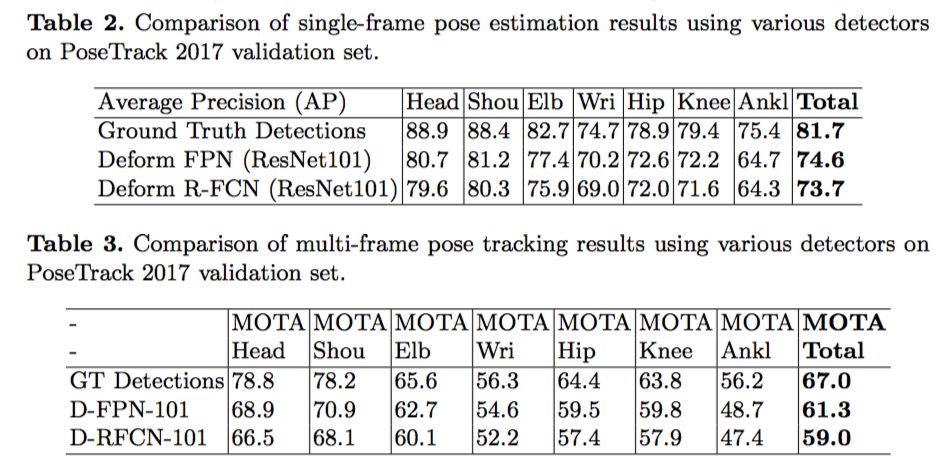
我们可以发现,deformable FPN对应的检测结果,在人体姿态识别和跟踪上准确率也更高。
并且,在使用检测的真值时,人体关键点识别和跟踪两项任务分别有7%和6%的提高空间。这意味如果使用专门针对人体检测的数据集(比如CrowdHuman)进行增广,并且单独训练人物这个类别,检测模块的准确率仍然有提升的空间,并可以帮助系统的准确率获得提升。
(2)单人姿态识别模块
主流的单人姿态识别方法是把RGB通道的输入图像经过完全卷积的regression运算,得到人体关键点的位置。具体来说,将人物图像ROI区块进行resize,得到一个固定大小的图像作为输入,比如256×256的大小。然后,根据关键点的位置,生成一个通道数为关键点个数(再外加一个代表背景通道)的heatmap tensor作为真值,分辨率往往要小于图像ROI区块,比如64×64。每个heatmap上都有一个以关键点中心而生成的符合高斯分布的blob。使用heatmap而不使用坐标值的原因是:直接使用坐标值进行回归会导致结果对干扰比较敏感,而人物的关键点并非一个具体的坐标点——一个坐标点真值周围的区域都可以认为是该关节点。
从2016年的Convolutional Pose Machine(CPM)开始,越来越多的人体姿态网络都是fully convolutional,纯粹的卷积运算。Hourglass网络是一个多尺度下进行关键点检测的网络,由于对多尺度的信息进行skip connection和concatenation,网络可以根据关键点的局部视觉特征和关键点之间的整体相互依赖关系得到更准确的真值。
Cascaded Pyramid Networks(CPN)[3] 是COCO 2018关键点任务的winner。和Hourglass相比,它提出了GlobalNet和RefineNet,其中GlobalNet是类似hourglass的结构,而RefineNet根据hard-keypoint mining对GlobalNet产生的heatmap结果进行refine。我们使用CPN的网络结构,进行单人姿态的识别。在得到关键点的热力图之后,我们利用FractalNet [4]中提出的cross-heatmap NMS的方法进行后处理,得到最终的关键点位置信息。
我们在COCO数据集上预训练,然后在PoseTrack数据集上进行finetune。因为COCO的关键点与PoseTrack的关键点种类和数量有所不同,COCO的数据对应的一些PoseTrack关键点是通过插值得到的。在使用COCO预训练之后,有些关键点的位置不够准确,需要在PoseTrack数据集上训练进行矫正。
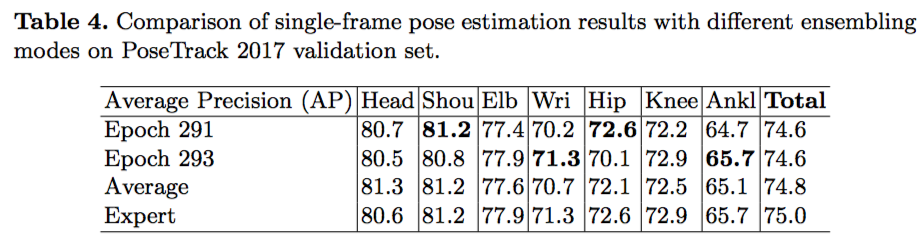
为了得到更高的准确率,我们使用两个模型来产生最终的关键点预测结果。下面图表中展示,通过均值的方法和专家方法对两个模型产生的结果进行综合,我们得到更准确的结果。两种方法中,专家方法的精度更高。
(3)多人姿态跟踪模块
多人姿态跟踪模块的功能是将检测模块和人体姿态识别模块产生的结果进行后处理,把视频中不同帧中的同一个人物关联起来,对视频中的每一个人物赋予一个独特的ID。我们采用PoseFlow [5] 的方法:首先利用deepmatch获得相邻帧之间的鲁棒点匹配,再根据一段时间内所有关键点的置信度信息通过优化方法得到“姿态流”——一个姿态流类似检测的人物在视频中产生的tubelet,区别在于姿态流包含的是关键点信息。最后,根据自定义的姿态流之间的距离,将姿态流进行最大值抑制和融合,得到最终的姿态流。同一个姿态流的人物和关键点ID都是一致的。
值得注意的是,在MOTA的评估标准下,丢失(missing)、错误(false positive)和不一致(mis-match)都会被惩罚,反映在结果上面。为了提高MOTA的值,我们在多人姿态跟踪模块之后,主动丢弃一些关键点——假如一个关键点的置信度低于阈值,就丢弃该关键点信息。这样一来,某一帧内的一个人物可能只提供部分关键点的信息,而不是全部。在某些遮挡的情况下,错误预测的关键点被丢弃了,因此可以获得更高的准确率。下面图表中展示了不同阈值对最终姿态识别和跟踪准确率的影响:
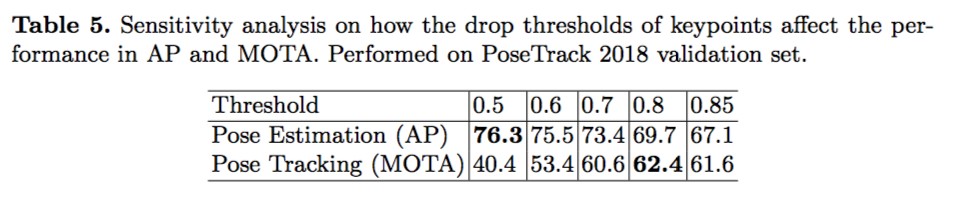
通过对不同阈值下不同人体位置的关键点留存率的分析,我们发现不同位置的关键点的难度不同,它们的置信度的概率分布并不相同。肩膀的关键点最容易预测,而四肢尤其是手腕脚腕的关键点难度最高。这很可能是因为这些部位的自由度更大,被遮挡的情况也更严重,由于半身像的存在,这些位置的训练数据也相对更少。下面图表展示了不同阈值下关键点的留存率:

假如能够自适应地确立不同位置的阈值,或许可以提高准确率。
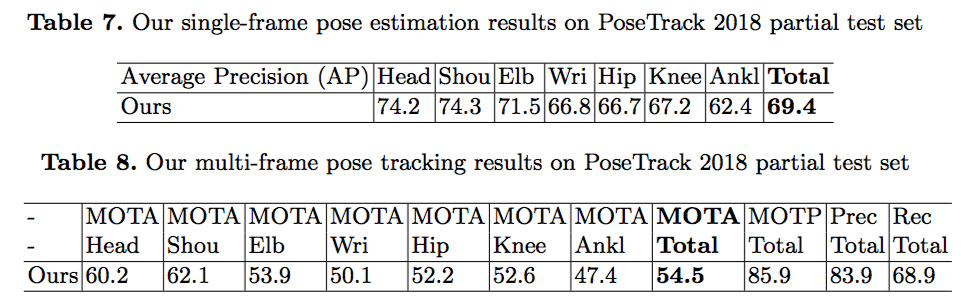
最终的人体关键点检测和跟踪的结果如下:
参考文献
[1] Ning, G., Liu, P., Fan, X., Zhang, C.: A Top-down Approach to Articulated Human Pose Estimation and Tracking. In: ECCV PoseTrack workshop (2018).
[2] Dai, J., Qi, H., Xiong, Y., Li, Y., Zhang, G., Hu, H., Wei, Y.: Deformable convolutional networks. In: ICCV (2017).
[3] Chen, Y., Wang, Z., Peng, Y., Zhang, Z., Yu, G., Sun, J.: Cascaded Pyramid Network for Multi-Person Pose Estimation. In: CVPR (2018)
[4] Ning, G., Zhang, Z., He, Z.: Knowledge-guided deep fractal neural networks for human pose estimation. IEEE Transactions on Multimedia20(5), 1246–1259 (2018)
[5] Xiu, Y., Li, J., Wang, H., Fang, Y., Lu, C.: Pose flow: Efficient online pose tracking. In: BMVC (2018)