
YOLO CPU Running Time Reduction: Basic Knowledge and Strategies
Guanghan Ning
3/7/2016
1. Basic Knowledge
By analyzing the CPU running time of the original YOLO model, we found that the majority of the time (>90%) is spent on the convolutional layers. Therefore, the reduction of time spent on convolutional layers is essential.
The time of convolutional layers is related to several settings:
- 1. the number of layers
- 2. the number of filters for each layer
- 3. the filter size
- 4. the size/dimension of the input image to each convolutional layer
The size of the weight file, accordingly, is related to the number of neuron-to-neuron connections, therefore also related to the settings mentioned above.
But note that the size of the weight file is also related to the input image number and their dimension fed to the fully connected layer. Since it is fully connected, if the input dimension is large, the overall number of weights will be much larger than that of the convolutional layers, resulting in the big size of the weight file.
The fully connected layer has less to do with the running time but more to do with the weight size. Consequently, we maxpool the convolutional outputs several times to make the input image feeding to the fully connected layers much smaller.
In order to reduce the running time but preserve the accuracy, our strategy is to reduce the number of filters for each convolutional layer but keep the network deep.
2. Strategy
The knowledge above is inspired by my experimental results. Recently, I have read a paper that addresses the same problem, . This paper confirms that reducing the running time while preserving the accuracy is feasible.
According to their research, they used 3 main strategies when designing DNN architectures.
1. Replace some 3*3 filters with 1*1 filters
2. Decrease the number of input channels/images to 3*3 filters
3. Downsample late in the network so that convolution layers have large activation maps.
Strategy 1&2 intend to decrease running time but preserve accuracy. Strategy 3 attempts to maximize accuracy on a limited budget of parameters.
3. Specific Configuration
cpuNet.cfg is the configuration file designed for a faster CPU-based YOLO model.
Time:
The running time on CPU is about 63ms. (YOLO fastest tiny model runs in 950ms with same CPU)
Performance:
The network is able to handle specific tasks under specific circumstances, where the variance of target objects is not as great as that of its real-world appearance. For example, in pictures taken by surveillance Cameras on highway, the vehicles have fewer variance than that from an automobile show. The convolutional layers in this network should have enough power for feature representation at this scale.
What I did with this model:
- Large number of filters in the first convolutional layer, keeping enough local information and visual cues
- Have a pair of convolutional layers with 1*1 filters, followed by a convolutional layer with 3*3 filters, the three of whom as a unit
- Downsample late: only downsample after each 3-convolutional-layer unit
- As the net goes deeper, double the number of filters for the third convolutional layer in the unit
- The fully connected layers can be kept unchanged, but need to make sure the number of neurons is correctly set according to the number of classes
Appendix 1: CPU running time for each layer of cpuNet
0. CROP : 0.287 ms
1. CONVOLUTIONAL : 56.453 ms
2. MAXPOOL : 1.280 ms
3. CONVOLUTIONAL : 0.182 ms
4. CONVOLUTIONAL : 0.068 ms
5. CONVOLUTIONAL : 0.546 ms
6. MAXPOOL : 0.056 ms
7. CONVOLUTIONAL : 0.044 ms
8. CONVOLUTIONAL : 0.045 ms
9. CONVOLUTIONAL : 0.440 ms
10. MAXPOOL : 0.030 ms
11. CONVOLUTIONAL : 0.415 ms
12. MAXPOOL : 0.016 ms
13. CONVOLUTIONAL : 0.376 ms
14. MAXPOOL : 0.008 ms
15. CONNECTED : 0.030 ms
16. CONNECTED : 0.387 ms
17. DROPOUT : 0.004 ms
18. CONNECTED : 2.295 ms
19. DETECTION : 0.004 ms
stop.jpg: Predicted in 0.063071 seconds.
stopsign: 0.71
Appendix 2: Demonstration Pictures
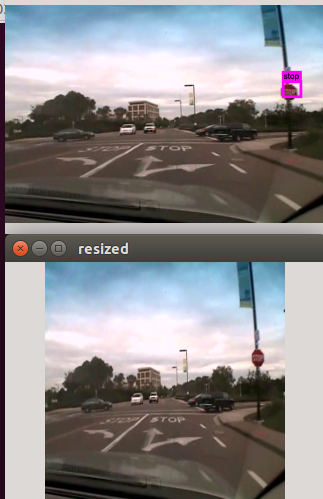
(The image is from the LISA dataset, which consists of 49 classes of US traffic signs)

(The image is from my own dataset, collected from google images )


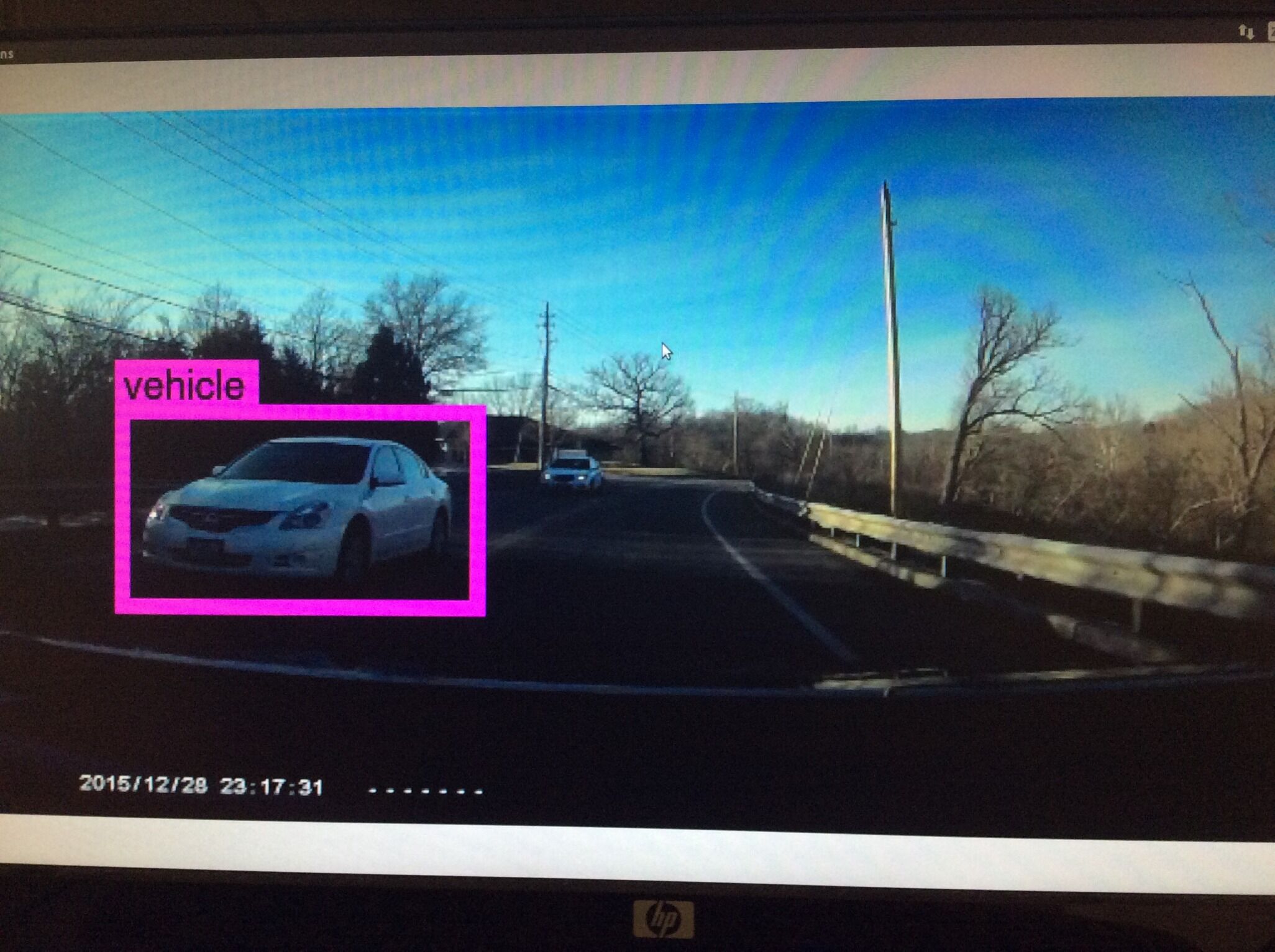
(The images are collected by a dashcam on a vehicle)
Leave a Reply
12 Comments on "YOLO CPU Running Time Reduction: Basic Knowledge and Strategies"
Hi, nice work and thanks for sharing.
Would the same methods apply while using a GPU? Do you think you would get such, 63ms vs 950ms, increase in speed employing a GPU? Did you look at that?
Thanks in advance.
It would get an increase in speed but not as much. On GPU, it is already pretty fast…For the tiny model, the jetson TX1 will run at around 20 fps. On Titan X, even the biggest YOLO model runs at 40fps.
I see. They have also released another interesting paper claiming substantial speed-ups.
http://arxiv.org/abs/1603.05279
It does not seem that they have a ready-to-test code right now. However, it would be interesting to compare/combine with your work.
I can’t find cpuNet.cfg… is there a link missing? Thanks for sharing!
Hey, check this out!
http://guanghan.info/miscellaneous/
Check this out:
http://guanghan.info/posts/
Hi, Guanghan!
I want to train my own data with your config file cpuNet10_1class.cfg, but I can’t find the pre-trained model(like darknet.conv.weights or extraction.conv.weights), could you share the pre-trained model?
Thanks in advance!
Hi Ning, thank you for your excelent work. You said you had read a paper that addressed the same problem and this paper confirmed that reducing the running time while preserving the accuracy is feasible. Could you give me the link to this paper? Thank you!
SqueezeNet
Great work. Have you (or anyone) tried this already for Yolo v2?
Thanks.
I also want to know this ,thanks
Hello
I want to train my own data and detect with cpuNet. is that possible?
since you told that “The fully connected layers can be kept unchanged, but need to make sure the number of neurons is correctly set according to the number of classes“
I have checked the original yolo.cfg file. if i trained in the original yolo file i have to set l 40 at the last layer and you have set it to 1573. is there any formula to change and train with gpu and detect with cpu.