
CenterNet and Its Variants
CenterNet[1] is a point-based object detection framework, which can be easily extended to multiple computer vision tasks including object tracking, instance segmentation, human pose estimation, 3d object detection, action detection, human-object interaction detection, and many others.
Instead of classifying pre-defined anchors into objects and regressing corresponding bounding box shapes, CenterNet regards objects as points, and directly regresses the center points of objects and the corresponding properties, e.g., the size of the bounding box, the offset, depth, or even the shape of the object. The properties of the object are highly customizable depending on the task and the problem to solve.
In this article, I will give an introduction to how CenterNet works, how it compares with classic detectors, and how to customize CenterNet to facilitate other tasks other than basic 2D object detection, by illustrating examples of some most recent Arxiv papers inspired by CenterNet.
The content of the article is given below:
- Quick review of classic object detection methods- CenterNet's feats and advantages- CenterNet's extensibility and variants- Implementations
1. Quick Glance at Classic Detectors
Please skip this section if you are quite familiar with classic detectors.
Recall ancient detectors such as R-CNN[2]. Dark times saw the emergence of deep learning-based object detectors, where powerful features are learned from data instead of carefully hand-crafted.
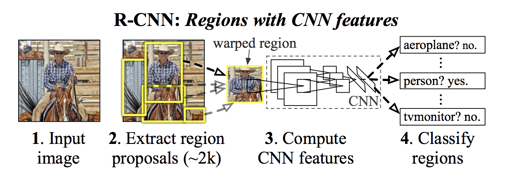
R-CNN is not very efficient as it follows old schemes similar to sliding window often adopted by traditional detectors, where each window or bounding box is classified as an object or the background. R-CNN replaces sliding window with Regional Proposal Network (RPN)[3], and Support Vector Machine (SVM)[4] classifier with a convolutional network.
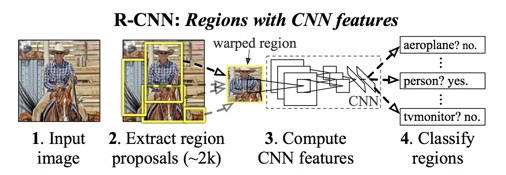
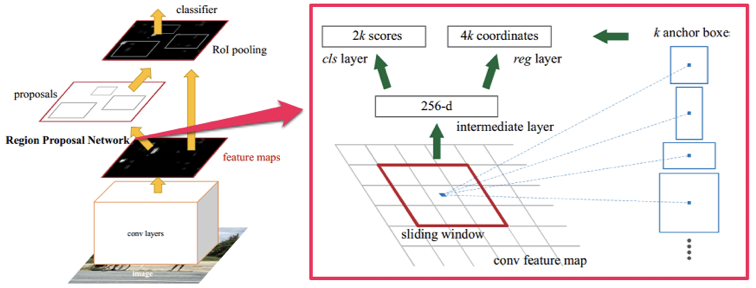
Its fast version pools features instead of cropping image patches; its faster version incorporates the once outsider RPN network. But at its core, three old yet stubborn things remain unchanged:
- The detection task is ultimately a classification task given a proposal.
- The proposal is anchor-based.
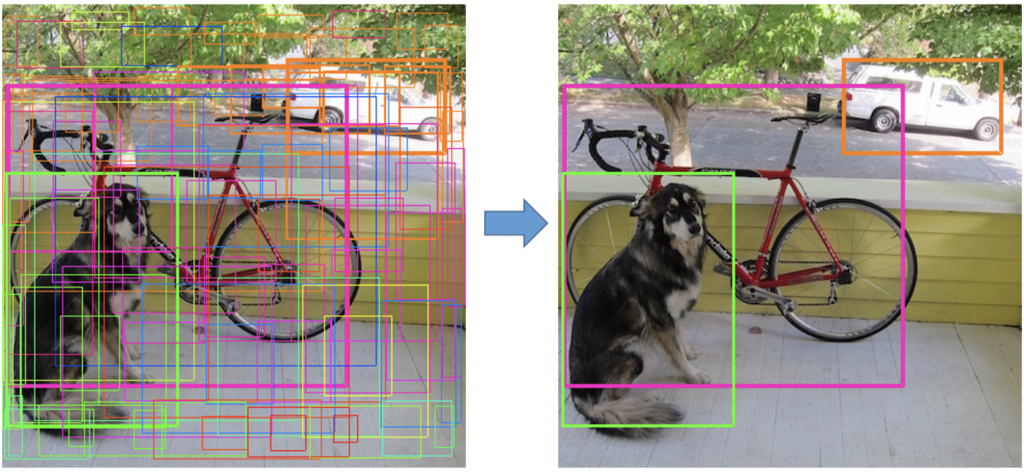
- Non-Maximum Suppression needs to be adopted as an auxiliary post-processing step.
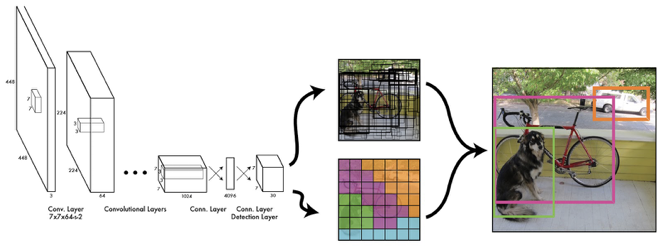
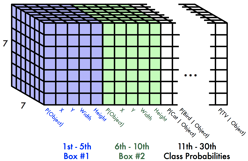
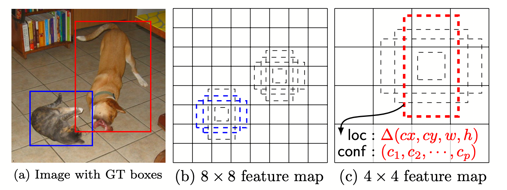
One-stage detectors became the popular rock star with the advent of YOLO[5] and SSD[6]. These one-stage detectors introduce direct regression of target locations, and use fixed-position anchors (although anchors can be multi-scale) that can be decoded with a pre-defined representation form.
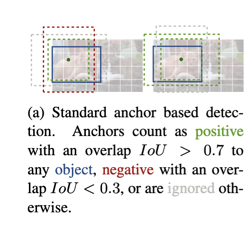
The advantage of anchor-based methods is that the prior knowledge provided by anchors constrains the aspect ratio and could prevent irregular detection shapes. However, the drawbacks (or at least the inconvenience) of anchors may outweigh the merits. Firstly, hyperparameters such as the number of anchor boxes will affect the detection performance. It is better that this hassle is avoided. Secondly, since all anchors contribute to the overall loss during training and that only the relatively few ground truth bounding boxes match positive anchors, the training process could become troublesome due to the unbalanced samples. Thirdly, anchor-based methods usually result in overlapping detections and resort to NMS for post-processing, which may be erroneous in some situations.

2. CenterNet’s feats and advantages
CenterNet solves the problems of anchor-based methods mentioned above.
- CenterNet is naturally compatible with multi-label problems.
- CenterNet is simple and elegant. It is single-stage, and does not need anchors or NMS.
- CenterNet provides a good balance between speed and accuracy.
- CenterNet provides “saved-my-life” experience for its practitioner.
- CenterNet is highly customizable and extensible. In fact, it has already been extended to various applications other than object detection.
Before I explain why I speak highly of CenterNet, what is CenterNet, at all? Well, CenterNet is yet another keypoint-based object detection method, just like CornerNet[7] and ExtremeNet[8]. Keypoint estimation is naturally a regression problem, whose targets are represented with a series of heatmaps, each channel representing a different keypoint genre. Since the receptive fields are spatially coherent, fully convolutional networks are perfect for this task.

CenterNet transforms the task of object detection from generating and classifying proposals into predicting objects’ centers (keypoints) and their corresponding attributes. For 2D object detection, the attributes are the width, height of the object, together with local offsets that recover pixel location in the original resolution from down-sampled heatmaps. Since keypoints of different genres can occur at the same position, CenterNet is naturally compatible with the multi-label problems.

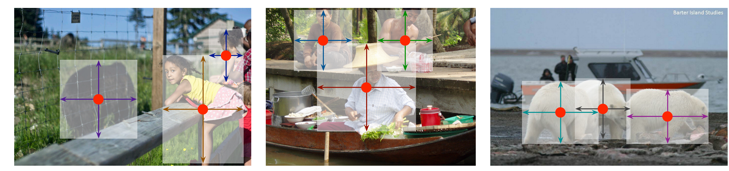
With direct heatmap regression, anchors are no longer required. During training, an object does not need to be assigned with proper anchor(s). Instead, only heatmaps for the entire image are generated as the regression target. When the heatmaps of centers are predicted during network inference, the local peaks are ranked based on the response or confidence, where top K objects are extracted. With the center positions, corresponding attributes are extracted across their respective channels at the same 2D position. In this way, objects are inferred and NMS becomes unnecessary.
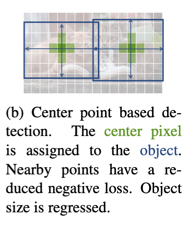
Compared with anchor-based detectors, CenterNet does not rely on prior knowledge from proposals, and this may impair its performance potential. Therefore, CenterNet may not be the perfect choice for solely pursuing SOTA results (although with excellent speed accuracy balance). But the simplicity and elegance are quite charming. In enterprise applications, such approaches may be more beneficial due to its simplicity, generality, and extensibility.
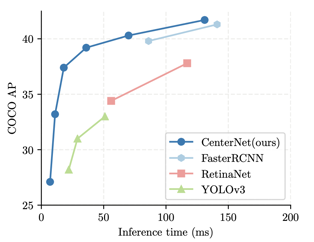
Performance aside, the experience of developing with or improve upon CenterNet as a researcher or engineer is probably much better than that with CenterNet’s counterparts like Detectron2. For instance, when you want to add negative samples during training to prevent false alarms, it requires some expertise to balance the positive and negative samples while training the proposal networks for Detectron2. But the process is much simpler with CenterNet, where the images can be directly used as negative samples. Just generate corresponding target heatmaps with no gaussian blobs and you are good to go.
In terms of CenterNet’s greatest feat, extensibility, please go ahead and read the next section.
3. CenterNet’s extensibility and variants
CenterNet provides two out-of-the-shelf applications in addition to 2D object detection: 3D object detection and 2D human pose estimation.


Recently, more and more variants of CenterNet have caught our attention. Let me introduce some of them to you real fast with their high-level concepts.
(1) CenterTrack: Tracking Objects as Points, Arxiv 2020[9]

A very straight forward way to extend 2D object detection is to add a temporal domain on top of the spatial domain for 2D object tracking. The original author of CenterNet Xingyi Zhou has come up with this “official” CenterTrack. The method is well described in the paper:
The network takes the current frame, the previous frame, and a Heatmap rendered from tracked object centers as inputs, and produces a center detection Heatmap for the current frame, the bounding box size map, and an offset map. At test time, object sizes and offsets are extracted from peaks in the heatmap.
Note that this method only takes care of the situation where the persons are not lost. In some situations, for instance, when a person disappears and reappears, a data association scheme is needed to solve the bipartite problem of matching new detections with track-lets in history. In this paper, the standard Hungarian algorithm is used.
(2) A Simple Baseline for Multi-Object Tracking, Arxiv 2020[10]
This is another method that extends CenterNet to object tracking. It complements the previous method with a Re-ID module, where the Re-ID features are simply additional properties for the CenterNet to regress in addition to the center points, the object size, and the offset. While simple in concept, it achieves SOTA performance on the MOT dataset and runs in real-time.
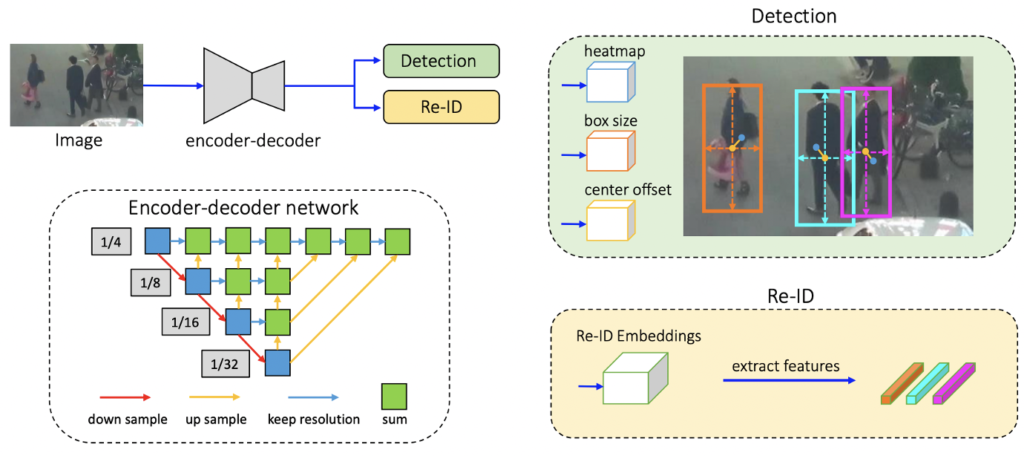
- (3) CenterMask: Single-Shot Instance Segmentation with Point Representation, CVPR 2020[11]
Semantic segmentation and instance segmentation are both more difficult tasks that 2D object detection. Pixel-level assignment is required for each object. For CenterNet, each object is encoded as a keypoint in the center, with bounding box properties. How to encode an object mask with the CenterNet framework is interesting to think about.
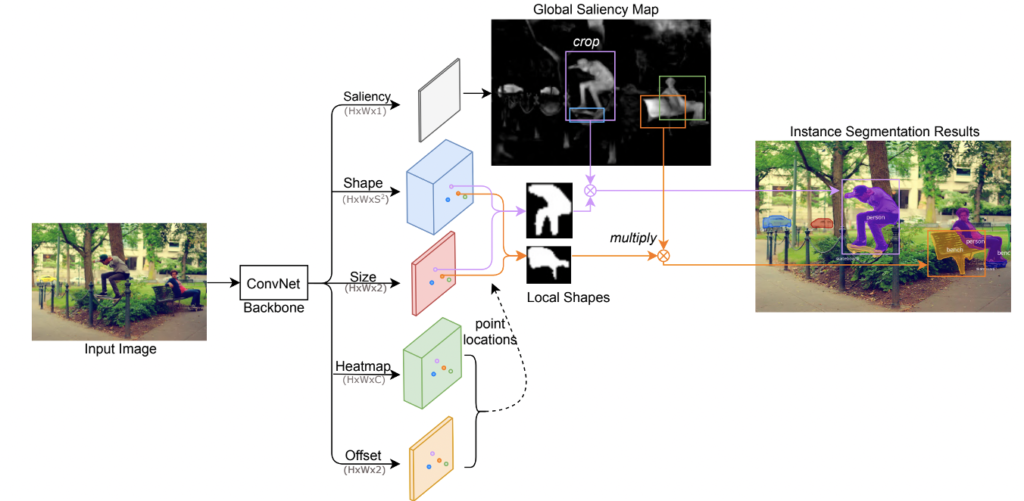
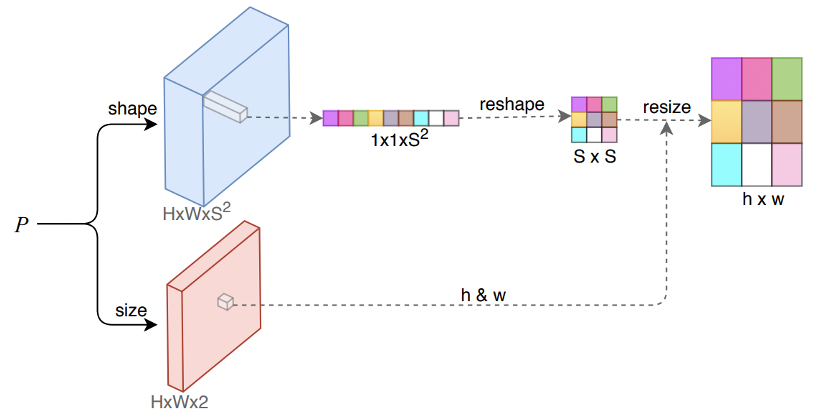
In this paper, the mask is comprised of two parts, the global saliency map and a local shape vector. The shape vector of size S2 is regressed with the CenterNet architecture, and considered to be flattened from an S×S binary mask. This binary mask is reshaped from the vector during inference and is used to provide the final segmentation results while multiplying with the global saliency map. Since each local shape corresponds to an object instance, the segmentation results are naturally at instance-level.
- (4) Actions as Moving Points, Arxiv 2020[12]
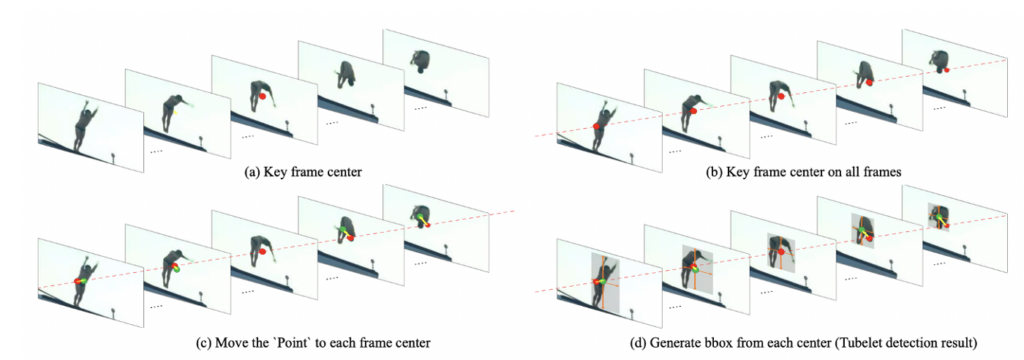
CenterNet “natively” supports 2D human pose estimation in the official implementation. For human-centric research, action detection and recognition is another important topic that is at a higher level than pose estimation. In this paper, actions are modeled as moving points, i.e., each action is considered a unique pattern of points moving with respect to the object (human) center in time series. It is straightforward to implement under the CenterNet architecture, as the movement is simply an offset vector (u,v) for each of the K points, resulting in K×2 channels to regress in the movement head.
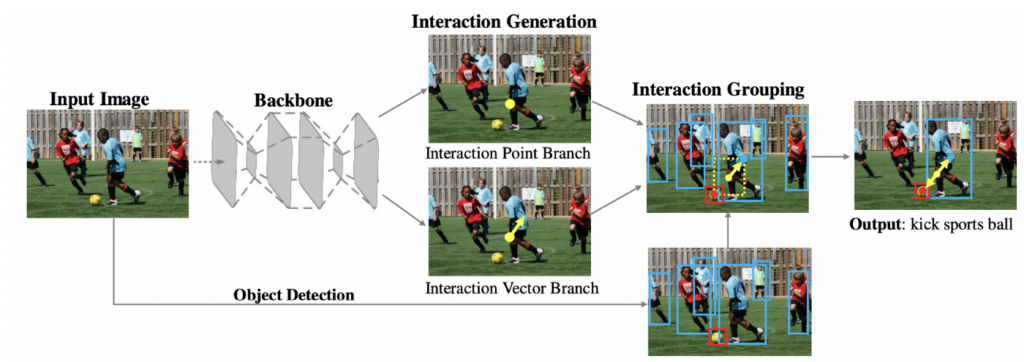
- (5) Learning Human-Object Interaction Detection using Interaction Points, Arxiv 2020[13]
Last but not least, let us take a glance at how Human-object Interaction (HOI) can be modeled as points. Although not strictly a CenterNet variant, it does share the same concept with CenterNet. The interaction is modeled as a keypoint together with a corresponding interaction vector that points from the interaction point to its action subject. With an additional interaction grouping stage, the triad (human, action, object) is detected.
4. Implementations
For your reference, I provide some links to the implementations of CenterNet, in case you do buy it after reading the post and want to get hands on CenterNet for research or just for fun.
- The official Pytorch implementation: CenterNet
- Another Pytorch implementation that claims to have even better results: CenterNet-better
- Tensorflow version is available here: CenterNet-Keras
- I have implemented a Gluon/MXNet port based on the official Pytorch repo: CenterNet-MXNet
Final Remarks
Nowadays, most research works in this field focus on incorporating things. There is nothing to blame for “collision-based innovation” (yeah I made it up). After all, that’s how our DNA evolved over the million years. It’s just that I particularly treasure works that simplify things; they are comparatively rare. Probably it is a matter of personal taste, but I hope that you enjoyed this introduction of CenterNet, and that this article has informed or inspired you in one way or another.
In terms of object detection methods that do not need anchors or NMS, DEtection TRansformer (DETR)[14] is another example. I will write about it in the next post (hopefully). Thanks for reading and be safe!
Reference
[1] Objects as Points: https://arxiv.org/pdf/1904.07850.pdf,
[2] Rich feature hierarchies for accurate object detection and semantic segmentation: https://arxiv.org/pdf/1311.2524.pdf,
[3] Selective Search: http://www.huppelen.nl/publications/selectiveSearchDraft.pdf,
[4] Support-Vector Networks: https://link.springer.com/content/pdf/10.1007/BF00994018.pdf,
[5] You only look once: https://pjreddie.com/darknet/yolo/,
[6] SSD: Single Shot MultiBox Detector: https://arxiv.org/abs/1512.02325,[6]
[7] CornerNet: Detecting Objects as Paired Keypoints: https://eccv2018.org/openaccess/content_ECCV_2018/papers/Hei_Law_CornerNet_Detecting_Objects_ECCV_2018_paper.pdf,
[8] Bottom-up Object Detection by Grouping Extreme and Center Points: https://arxiv.org/abs/1901.08043,
[9] CenterTrack: https://arxiv.org/pdf/2004.01177.pdf,
[10] Simple Baseline for MOT: https://arxiv.org/pdf/2004.01888.pdf,
[11] CenterMask: https://arxiv.org/pdf/2004.04446.pdf,
[12] Action as Moving Points: https://arxiv.org/pdf/2001.04608.pdf,
[13] Interaction as Points: https://arxiv.org/pdf/2003.14023.pdf,
[14] End-to-End Object Detection with Transformers: https://arxiv.org/pdf/2005.12872.pdf,
Leave a Reply
Be the First to Comment!