
© 2016. All rights reserved.
© 2016. All rights reserved.
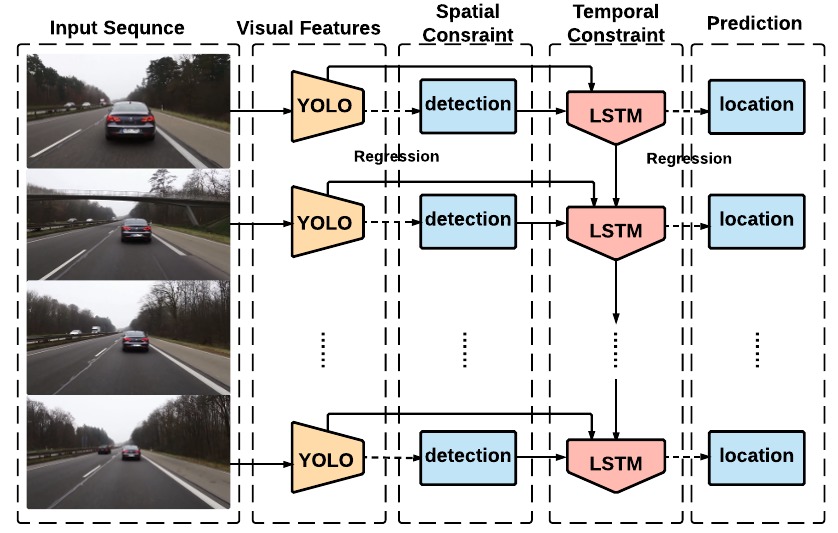
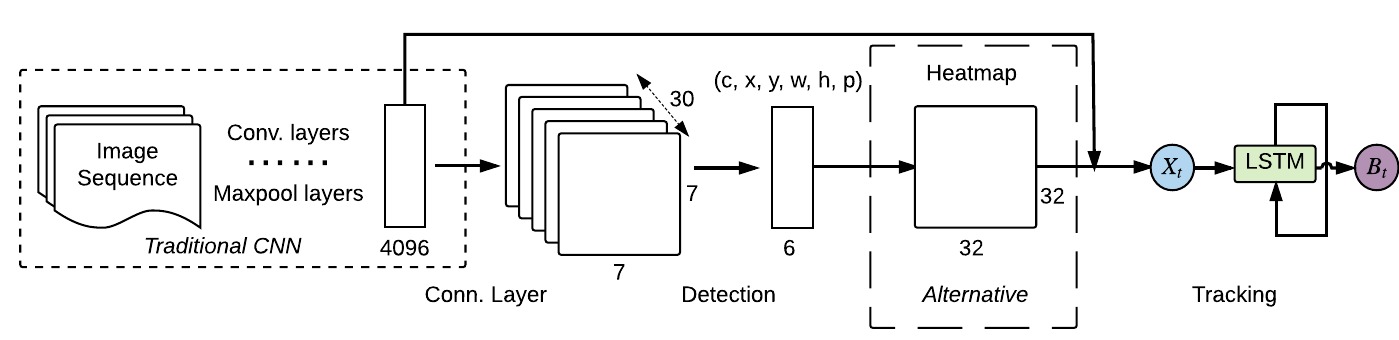

 ROLO is effective due to several reasons: (1) the representation power of the high-level visual features from the convNets, (2) the feature interpretation power of LSTM, therefore the ability to detect visual objects, which is spatially supervised by a location or heatmap vector, (3) the capability of regressing effectively with spatio-temporal information.
ROLO is effective due to several reasons: (1) the representation power of the high-level visual features from the convNets, (2) the feature interpretation power of LSTM, therefore the ability to detect visual objects, which is spatially supervised by a location or heatmap vector, (3) the capability of regressing effectively with spatio-temporal information.

 It is shown in the above figure that ROLO tracks the object in near-complete occlusions.
Even though two similar targets simultaneously occur in this video, ROLO tracks the correct target as the detection module inherently feeds the LSTM unit with spatial constraint.
Note that between frame 47-60, YOLO fails in detection but ROLO does not lose the track.
The heatmap is involved with minor noise when no detection is presented as the similar target is still in sight. Nevertheless, ROLO has more confidence on the real target even when it is fully occluded, as ROLO exploits its history of locations as well as its visual features.
It is shown in the above figure that ROLO tracks the object in near-complete occlusions.
Even though two similar targets simultaneously occur in this video, ROLO tracks the correct target as the detection module inherently feeds the LSTM unit with spatial constraint.
Note that between frame 47-60, YOLO fails in detection but ROLO does not lose the track.
The heatmap is involved with minor noise when no detection is presented as the similar target is still in sight. Nevertheless, ROLO has more confidence on the real target even when it is fully occluded, as ROLO exploits its history of locations as well as its visual features.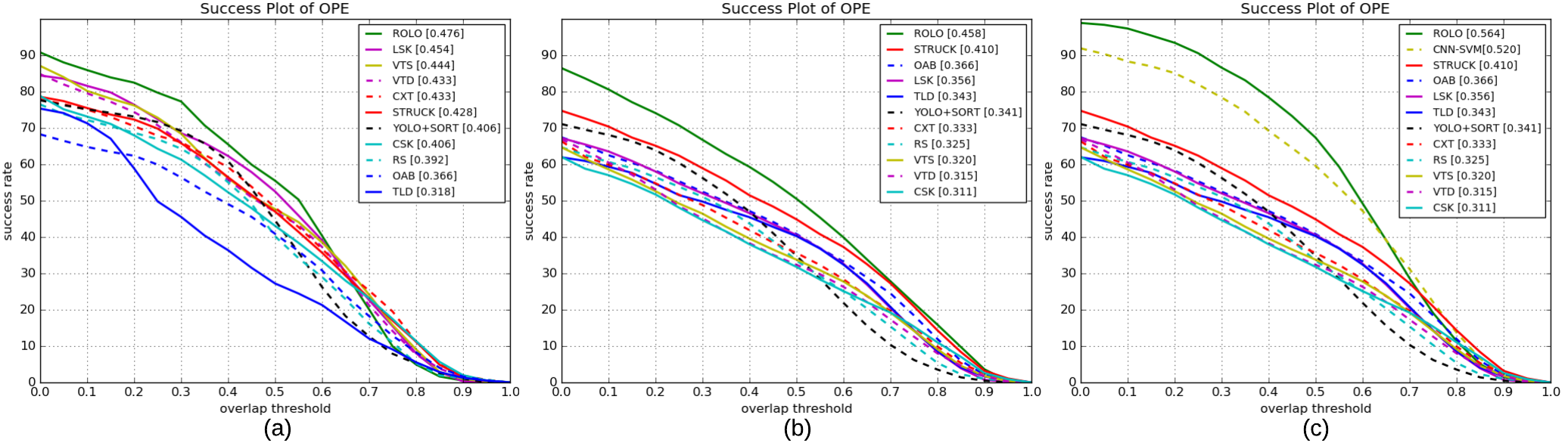
|
[Arxiv]
[Github] If you find this work useful, please cite: |