PoSeg Network and its AR applications
The PoSeg Network
The PoSeg Network is named so because it is a joint network that works on two tasks: Human
Pose Estimation and the Portrait
Segmentation (I am not the worst network namer in this world, I promise).
The two tasks are very similar. They are both regressing raw image input or visual features into pixel-level outputs.
For semantic segmentation, the output layer is usually a softmax layer followed by a logistic regression layer, and then maps the one-hot vector outputs into crisp labels.
For human pose estimation, the output layer can just be a convolutional layer, with or without non-liniarities, whose heatmaps initialized by a Gaussian distribution centered at each keypoint position.
The overview of the PoSeg network is illustrated in the figure below:
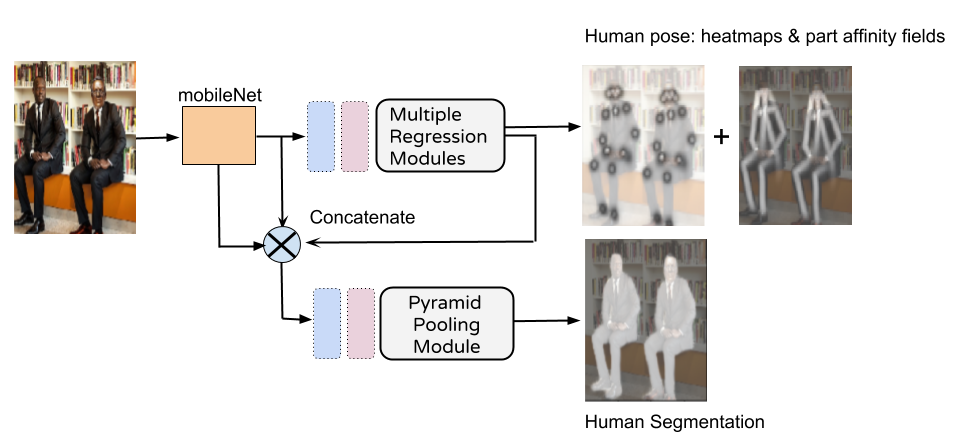
Literally, the two tasks take in the same visual features extracted at lower-level and mid-level and merged before feeding into the two branches.
This is to extract visual features as well as context information, sort of :)
Then for the pose part, we are just imitating what PAF [1] did, which is, regressing the features into keypoint heatmaps and the part affinity fields.
For the segmentation part, we are follwing the design of the PSPNet [2], by feeding the features into a Pyramid Pooling Module.
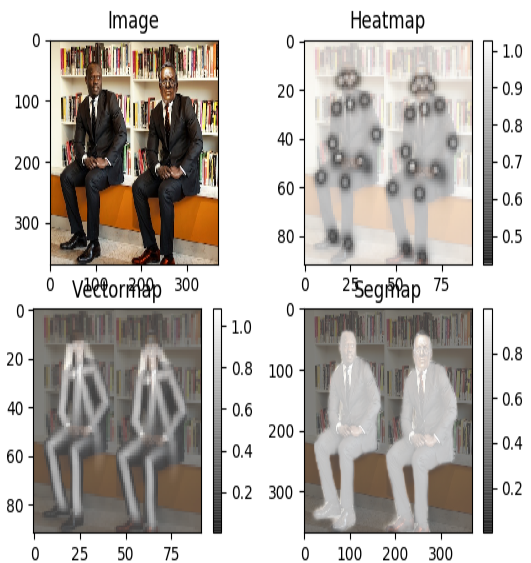
Some example of the regression outputs are illustrated below:
AR Applications
The PoSeg network captures both the semantic-level segmentation (Portrait Segmentation in this case) and the keypoints of the human body.
This brings some interesting applications. For instance, the keypoints of human pose can be used to locate the shoulder, while the segmented mask can be used for the image overlay.
The following figure shows the special effect "Winged" based on these two observations.

Another application is to make the person look thinner. Since we have the keypoints of the person, we can squeeze the person area horizontally.
In order to make the person look natural, we keep the area of the head original. This is done by working on the circular area located by the head keypoints.
The following image shows the "Thinner" effect.

"Okay, it looks cool and all, but this is not really AR or very high-tech..." You may say. Well, I totally agree with you.
But that's what I did for this project. Hope you enjoyed it anyway.
REFERENCE
[1] Cao, Zhe, et al. "Realtime multi-person 2d pose estimation using part affinity fields." arXiv preprint arXiv:1611.08050 (2016).
[2] Zhao, Hengshuang, et al. "Pyramid scene parsing network." IEEE Conf. on Computer Vision and Pattern Recognition (CVPR). 2017.
